Our Mission
Modern end-to-end data pipelines are highly complex and unoptimized. They combine code from different frontends (e.g., SQL, Beam, Keras), declared in different programming languages (e.g., Python, Scala) and execute across many backend runtimes (e.g., Spark, Flink, Tensorflow). Data and intermediate results take a long and slow path through excessive materialization, conversions down to different partially supported hardware accelerators. End-to-End guarantees are typically complex to reason due to the mismatch of processing semantics across runtimes.
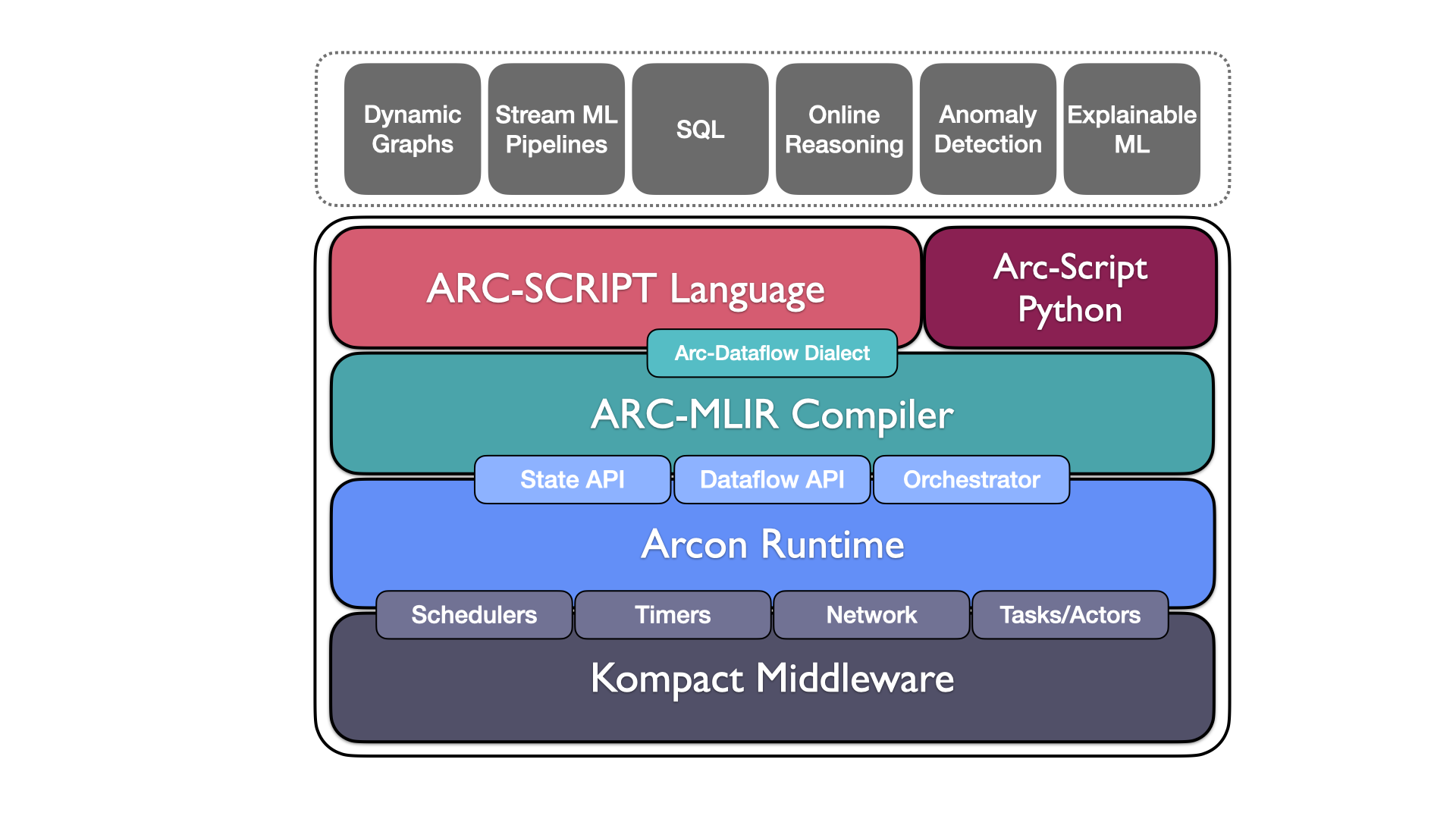
The Continuous Deep Analytics (CDA) project aims to shape the next-generation software for scalable, data-driven applications and pipelines. Our work binds state of the art mechanisms in compiler and database technology together with hardware-accelerated machine learning and distributed stream processing.
Architecture
The CDA project is currently composed out of 1) Arc: an Intermediate Representation (IR) for batch and stream data computation, 2) Arcon: A distributed execution runtime for Arc programs and 3) Kompact: a component- and actor-based middleware for programming distributed systems that is written entirely in Rust.